About Me
- Email: aanchalll71@gmail.com
- City: New York
- Education: M.S. in Analytics
B.S. in Computational Mathematics - Read References: Recommedations
- Certificate: SQL ADVANCED LEVEL CERTIFICATE
TABLEAU DESKTOP SPECIALIST
- LinkedIn: linkedin.com/in/anchal
- GitHub:github.com/anchal
Skills
Professional Experience
Product Data Analyst
Location: New York, NY
Duration: APR 2024 - PRESENT
- Built analytics frameworks for various fintech products for the retail sector
Associate Manager, Business Intelligence
Location: New York, NY
Duration: SEP 2023 - Mar 2024
- Developed scalable data solutions and delivered actionable insights to senior management and stakeholders, driving strategic decisions, optimizing remarketing operations through advanced analytics.
Data Scientist
Practicum Project- University of California Davis
FASHOM
My Portfolio
- All
- Featured Projects
- Machine Learning
- Stats Models
- Tableau Dashboards
- Web Scraping

Image Classification - Clothing Attributes
This project involved image tagging for a clothing brand, where the focus was not only on classifying clothing types such as tops and dresses but also identifying specific attributes like neck design, sleeve length, and print pattern. Instead of solely categorizing clothing items, the aim was to classify and label various attributes associated with the garments, enabling a more detailed understanding of the clothing inventory.

Printer Repurchase Propensity
Our team tackled the challenge of leveraging first-party data for customer segmentation, customer audience retargeting and forecast printer purchase propensity for HP, following Google's announcement of dropping support for third-party cookies. The Hackathon was Sponsored by Z by HP & Google.

Marketing Mix Modeling
The goal of this project is to determine the effectiveness of advertising activities on the sales performance of a cosmetics firm. The firm has launched a product four years ago and wants to assess the impact of its advertising spends across various media channels on sales. This report aims to provide insights into the effectiveness of their advertising strategies and develop a preliminary allocation model that can guide the firm's decision-making process.

Prediciting Student Performance & Learning Analytics
This project aims to predict student performance in real-time during game-based learning using one of the largest open datasets of game logs. The goal is to advance research into knowledge-tracing methods for game-based learning, helping developers create more effective educational games and providing educators with dashboards and analytic tools. Although game-based learning is becoming increasingly popular, there are limited open datasets available to apply data science and learning analytic principles. The Field Day Lab, a publicly-funded research lab, designs educational games for various subjects and age groups, making use of game data to understand how people learn. The lab partners with nonprofits like The Learning Agency Lab to develop the science of learning-based tools and programs for the social good.

NLP & Multi Label Classification
The "Toxic Comment Classification" project aims to identify and classify toxic comments in online platforms. The project falls under the category of Natural Language Processing (NLP) and involves the task of multi-label classification. The goal is to predict whether a comment belongs to one or more categories such as toxic, severe-toxic, obscene, threat, insult, or identity-hate. Problem transformation methods like Binary Relevance, Classifier Chain have been used

World Happiness Score
This project aims to explore and visualize happiness scores across the world, examining factors like economic growth, government trust, and the impact of COVID-19. The project uses Tableau for in-depth visual analysis, including various visualizations and hypothesis testing. It explores the relationship between happiness and freedom, as well as government trust and GDP per capita. The findings suggest a correlation between government trust and happiness scores, as well as a positive relationship between GDP and happiness.

New Feature Performance Evaluation
Introducing an Online Community at a Mobile Game Company and evaluating feature performance using Diff and Diff and Customer Lifetime Value. Developed a quasi-experimental design using DID estimation to quantify the effect of a new online community feature. Utilized logistic regression to predict churn, evaluate CLV and measure the efficacy of campaigns for retention growth.

Dimension Reduction & K-Means Clustering
This project explores the Madelon dataset using k-means clustering and principal component analysis (PCA). The dataset consists of 500 features and 2,600 data points with a non-linear structure. The code includes steps for clustering with various k values, applying PCA for dimensionality reduction, and comparing results before and after PCA. Evaluation metrics and visualization techniques are used to assess the quality of clusters. The project demonstrates the advantages of utilizing dimensionality reduction before clustering high-dimensional datasets.

Spam Classifier
The Email Spam Classifier project is an end-to-end code that accurately classifies text messages as spam or ham (non-spam) based on their content. Its main objective is to alert users to spam messages and protect them from fraudulent activities. The project utilizes a dataset from the UCI Machine Learning Repository and performs data cleansing and text preprocessing to prepare the data for analysis. Various classification models, including Naive Bayes, Logistic Regression, Decision Tree Classifier, Random Forest Classifier, Ada-Boost Classifier, and Bagging Classifier, are created and evaluated based on accuracy and precision. The Multinomial Naive Bayes algorithm is found to deliver good accuracy and precision, making it the preferred choice.

Fraud Detection
A loan offering company aims to develop a default risk model using historical loan records. Used R-studio to build default risk model that gives a risk score for each customer in the test set, select the final model, and report the Mean Absolute Error (MAE) on the test data.

Customer Acquistion Analysis
This project focuses on analyzing the effectiveness of a digital advertising campaign conducted by Game Fun, a leading developer of casual mobile games. The goal of the campaign was to improve customer acquisition by running an A/B experiment using online display banners. The project involves performing a comprehensive data analysis, evaluating the impact of the experiment on various customer segments, and providing recommendations based on the findings.

Image Compression
Image Compression using PCA in R-Studio
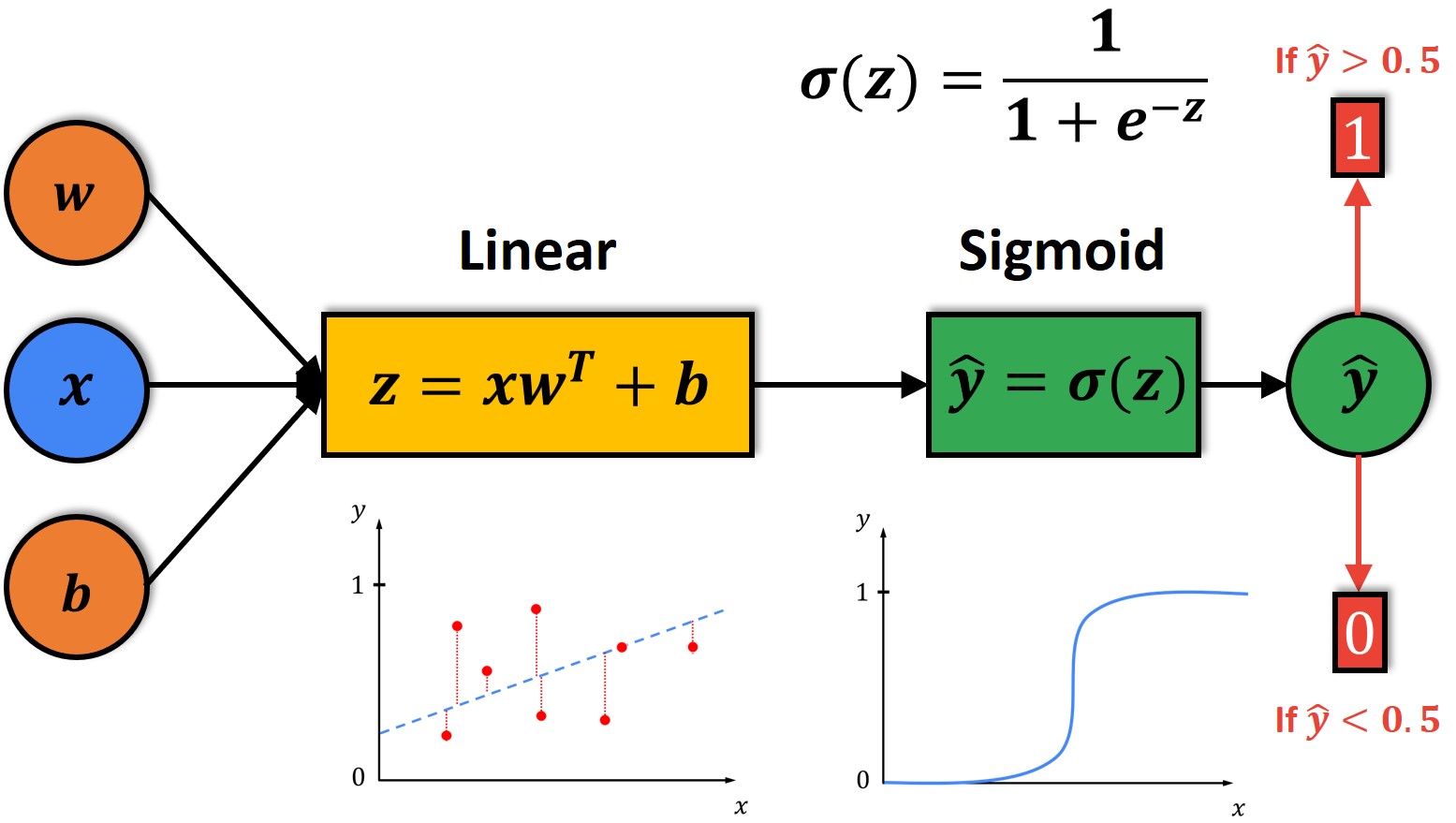
Logistic Regression
This project involves analyzing the effects of interactions in linear regression, developing logistic regression models, interpreting model coefficients, and creating interaction plots. Additionally, the project examines the effects of income and change in savings on the likelihood of buying a house through various plots

Reddit Comment Scraper
This project focuses on scraping comments from a chosen post on Reddit and storing them in a MongoDB collection. The script retrieves the first 5 comment threads with a maximum depth of 3 and organizes the comments in a nested structure. Additionally, a MongoDB query is provided to retrieve all the replies and nested replies for a given comment in a specific format.

Top Pizzeria in San Francisco (Web Scraping)
This project utilizes Selenium and web scraping techniques to gather and analyze data from two different websites. The first part involves scraping details of the most expensive Bored Ape Yacht Club apes with "Solid gold" fur from OpenSea. The second part focuses on scraping information about the top 30 pizzerias in San Francisco from yellowpages.com, parsing the data, and storing it in a MongoDB collection. The code showcases the flexibility to adapt for scraping other websites and storing data in various formats.

Wine Web Scraping
This project focuses on web scraping using Selenium to extract data from the Vivino wine website. It involves navigating the website, scraping wine pages, and storing the collected data in a MongoDB database. The project aims to automate the collection of wine data for further analysis.
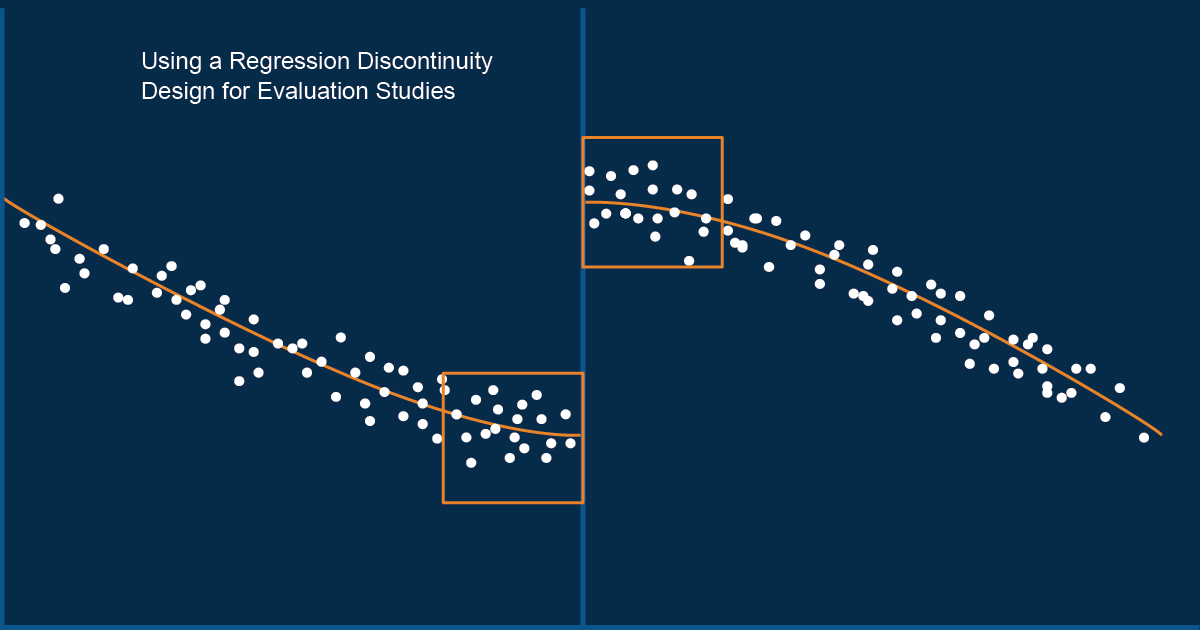
Regression Discontinuity Design
In this project, the effect of drinking on the likelihood of death will be explored using the drinking.csv dataset. The RDD (Regression Discontinuity Design) method will be applied to determine if alcohol consumption increases the risk of death. Results will be analyzed to provide insights on whether the legal drinking age should be lowered from 21.
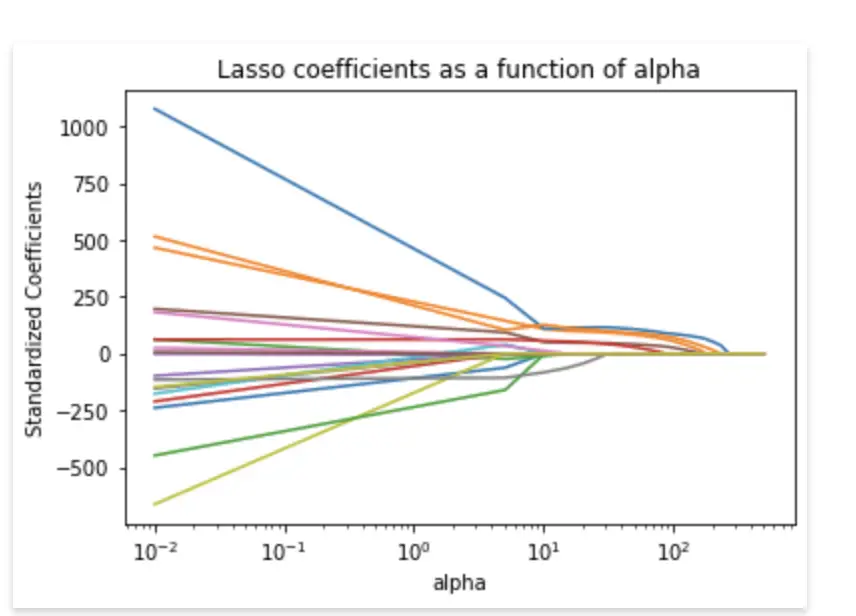
Lasso Regression with Cross validation
In this project, the heart disease dataset is analyzed using R. Statistical analyses are performed, including sample subset selection, training subset selection, simple linear regression modeling, cross-validation, and lasso regression. The project aims to predict the probability of heart attack and evaluate the model's performance. AIC and AICc are used to assess the model's quality.

Recommendation System
Developed recommendation engine for customer analytics -Applied collaborative filtering techniques(user and item based) with different metrics on movies to predict ratings for existing as well as new customers and determined which model predicts the best.
Contact Me
Let's Connect!
Social Profiles
Email Me
aanchalll71@gmail.com